
Energiamurroksen myötä uusiutuvien energialähteiden, kuten aurinkoenergian, käyttö on yleistynyt merkittävästi. Haasteena uusiutuvassa energiantuotannossa on kuitenkin tuotannon ja kulutuksen ajallinen epäsuhta: energiaa tuotetaan usein silloin, kun kulutustarve on vähäistä. Tämän vuoksi tuotettu energia pyritään varastoimaan esimerkiksi akkujärjestelmiin, sähköautoihin tai lämminvesivaraajiin, jotta sitä voidaan hyödyntää myöhemmin kulutushuippujen tasaamiseen. Kulutuksen tasaamisen lisäksi kuluttajaa kiinnostaa energiasta syntyvien kustannusten pienentäminen. Kustannuksia voidaan pienentää käyttämällä mahdollisimman paljon omaa tuotantoa, sekä ostamalla energiaa, silloin kun se on halpaa.
Energiavirtojen optimointi vaatii monien muuttujien, kuten energiankulutuksen, -tuotannon sekä -hinnan seuraamista. Tämän vuoksi energiavirtojen hallintaan kehitetään yhä enemmän automatisoituja ratkaisuja. Esimerkiksi releet voivat ohjata sähkölaitteita pörssisähkön hinnan perusteella ilman käyttäjän aktiivista osallistumista. Uusimpana lähestymistapana on tekoälyn hyödyntäminen, erityisesti koneoppimismenetelmien soveltaminen kulutuksen ja tuotannon ennustamiseen sekä energiankäytön ohjaukseen. Vahvistusoppiminen on yksi koneoppimisen osa-ala, jota on testattu energiavirtojen optimointiin.
Vahvistusoppiminen
Vahvistusoppiminen (Reinforcement Learning) on koneoppimisen oppimismenetelmä, jossa niin kutsuttu agentti opettelee tekemään päätöksiä ympäristöstä yrityksen ja erehdyksen kautta. Agentti on mikä tahansa järjestelmä, joka pystyy tekemään päätöksiä tai toimimaan ympäristön mukaisesti, esimerkkinä agentista ovat robotit ja itseohjautuvat autot. Agentti havainnoi ympäristön tilaa, tekee sen perusteella päätöksiä ja saa toiminnastaan palautetta palkkiofunktion muodossa (Sutton & Barto, 2018, s. 1–2).
Vahvistusoppimisen keskeisimmät komponentit ovat agentti, ympäristö, toimet ja palkkiot. Ympäristö on simuloitu tilanne, jossa agentti toimii. Toimet ovat vaihtoehtoja, joita agentti voi suorittaa ympäristössä. Palkkio on agentin saama negatiivinen tai positiivinen palaute, jonka se saa ympäristöstä toimiensa perusteella.
Syvävahvistusoppiminen (Deep Reinforcement Learning, DRL) yhdistää syväoppimisen ja vahvistusoppimisen menetelmät. DRL-mallit kykenevät oppimaan monimutkaisten järjestelmien dynamiikkaa ja optimoimaan toimintaa suorituskykyä mittaavan palkkioarvon perusteella. Näiden mallien etuna on kyky käsitellä suurta ja moniulotteista dataa, joita esiintyy esimerkiksi energiajärjestelmissä.
DRL-algoritmeja on sovellettu useissa energiasektorin käyttötapauksissa, kuten rakennusten energiavirtojen hallinnassa, sähkönkulutuksen optimoinnissa ja kulutuksen minimoinnissa (Shengren et al., 2023, s. 2). DRL on osoittautunut tehokkaaksi ohjausmenetelmäksi erityisesti datapohjaisissa tutkimusmalleissa, ja sen käyttöä on tutkittu niin kotitalouksien energiavirtojen hallinnassa kuin sähköverkkojen operatiivisessa ohjauksessa. Lisäksi DRL-malleja, kuten Proximal Policy Optimization (PPO), on hyödynnetty energiavirtojen optimointisovelluksissa.
DRL-algoritmin soveltuvuus energiayhteisön optimointiin
Älykkäät Energiayhteisöt -hanke tukee siirtymää kohti vihreämpää ja kestävämpää energiajärjestelmää ja pyrkii löytämään uusia ratkaisuja energiaohjauksen automatisointiin. Hankkeen toimeksiantona toteutetussa diplomityössä (Pohjonen 2025) testattiin DRL-algoritmin toimivuutta energiayhteisön energiavirtojen optimoinnissa.
Työssä luotiin syvävahvistusoppija (DRL)-pohjainen suosittelija, joka antaa energiayhteisölle suosituksia energiavirtojen käytöstä 24 tunnin ajalle. DRL-algoritmin ympäristönä on simuloitu energiayhteisö. Ympäristö sisältää 24 tunnin energiankulutus ja – tuotanto ennusteen, tiedon energian spot-hinnasta sekä akun varaustasosta. Agentilla on ympäristössä kolme mahdollista toimintoa: osta energiaa verkosta, varastoi energiaa akkuun tai käytä energiaa akusta. Agentin ensisijaisena tavoitteena on minimoida energiankustannukset.
Agentti saa positiivista palautetta, jos se varastoi ylituotantoa, käyttää energiaa akusta tai ostaa energiaa, kun se on halpaa. Ympäristö antaa agentille negatiivisen palautteen, jos energiaa ostetaan, kun se on kallista. Kallis ja halpa hinta määriteltiin hakemalla datasta halvimmat ja kalleimmat tunnit päivän keskiarvoon nähden.
Agentti saa negatiivista palautetta myös, jos se ylittää akun maksimi tai minimi varaustasot. Agentti käy ympäristöä läpi ja sen tavoitteena on saada mahdollisimman suuri positiivinen palaute. Simuloinnissa tarkasteltiin suosittelijan toimintaa kerrostalo- ja kauppakiinteistön kulutusprofiileilla.
Simulointitulokset suosittelijan toiminnasta
Kuvassa 1 esitetään yhden kerrostalokohteen tulokset kesäpäivälle ja kuvassa 2 on esitetty saman kohteen tulokset talvipäivälle. Kuvaajasta voidaan tarkastella ympäristöön syötettyjä tietoja energiankulutuksesta, -tuotannosta ja -hinnasta. Lisäksi siitä voidaan seurata akun varaustason muutoksia suosittelijan antamien suositusten mukaisesti.
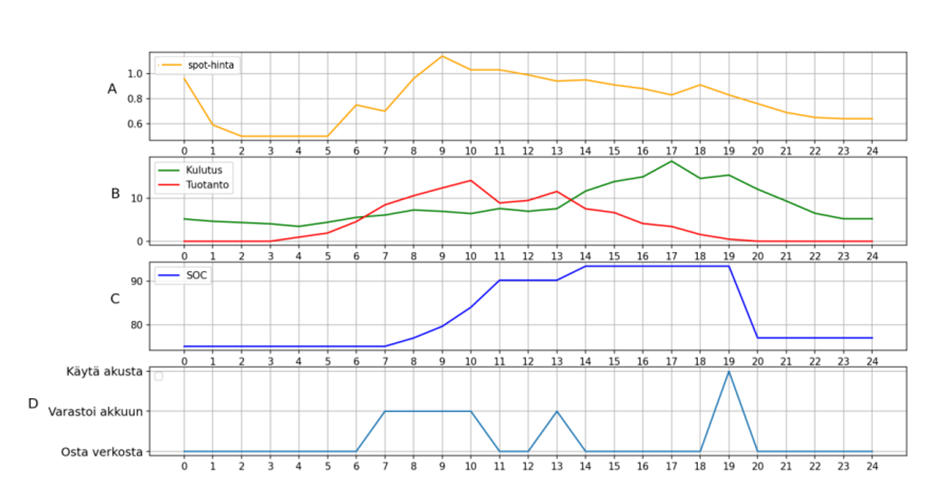
Kuvan 1 perusteella vuorokauden alkuhetkinä energiankulutus on vähäistä, eikä omaa tuotantoa ole saatavilla. Energian hinta on kuitenkin alhainen, minkä vuoksi suosittelija ehdottaa energian ostamista suoraan sähköverkosta. Kello 6 aikaan järjestelmässä esiintyy ylituotantoa, joka varastoidaan akustoon, kunnes akku saavuttaa täyden varaustason.
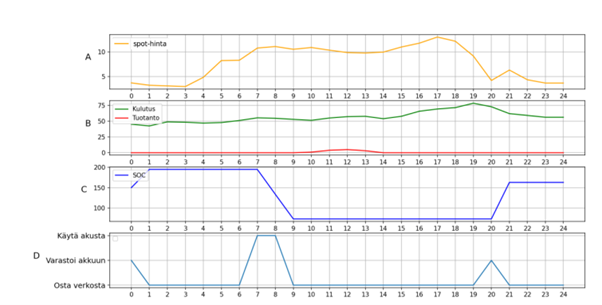
Kuvasta 2 nähdään, että talvella tuotantoa on paljon vähemmän, jolloin suosittelijan tekemät suositukset ovat erilaisia kesäaikaan verrattuna. Suosittelija ostaa energiaa verkosta sen ollessa halpaa, ja käyttää energiaa akusta, niin kauan kuin varausta on jäljellä.
Suosittelija antoi kerrostalokohteille optimaalisempia suosituksia kuin kauppakiinteistölle, kuvassa 3 on esitetty suosittelijan toiminnot kauppakiinteistölle kesällä ja kuvassa 4 talvella.
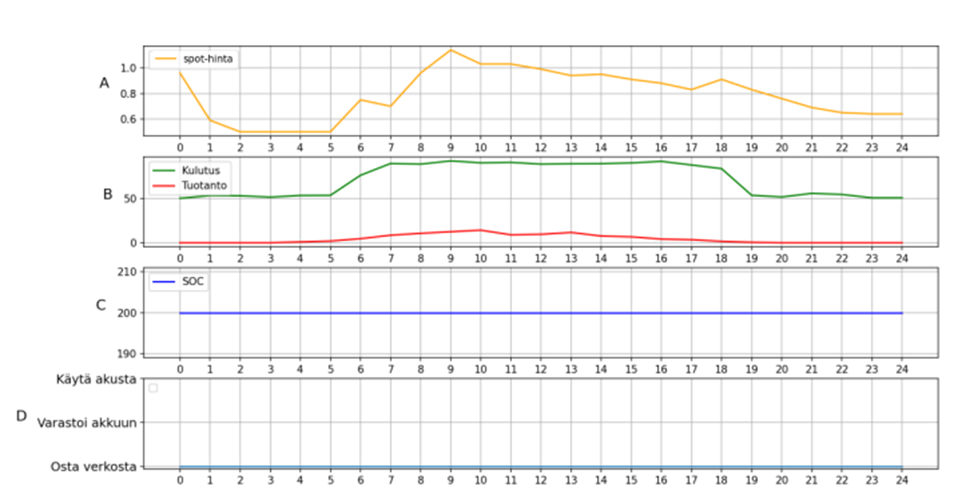
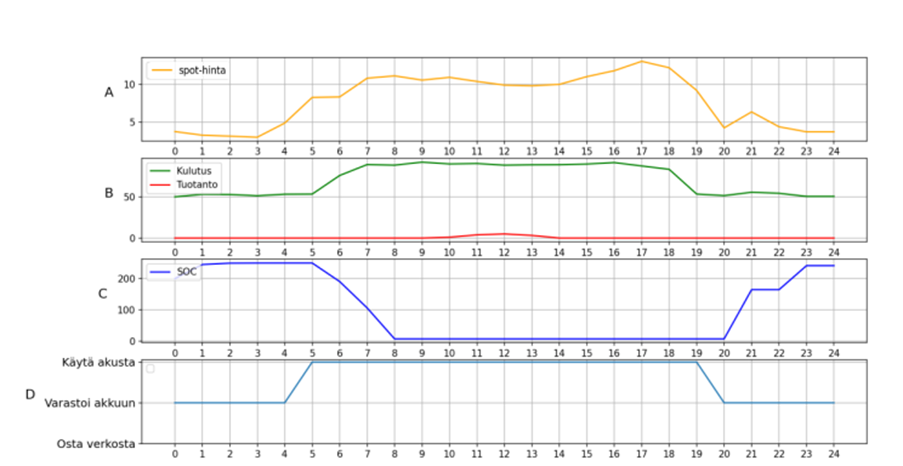
Kauppakiinteistön tapauksessa talvella suosittelija jäi jumiin suosittelemaan energian käyttöä akustosta, vaikka akusto olisi jo tyhjä. Kesällä suosittelija ehdottaa vain energian ostamista verkosta. Kauppakiinteistön tapauksessa energiantuotanto on hyvin pientä, koska simuloinneissa käytettiin samaa paneelikokoa, kuin kerrostaloille. Paremman kuvan todellisuudesta voitaisiin saada simuloimalla suurempi energiantuotanto kauppakiinteistölle.
Optimoijan ongelmat ja mahdollisuudet
Suosittelija toimi kohtuullisesti kerrostalokohteissa, mutta ei lainkaan kauppakiinteistössä. Toiminnan parantamiseksi agentin palautealgoritmia tulisi muokata kohdekohtaisesti. Kauppakiinteistön osalta algoritmiin tulisi lisätä voimakkaampi negatiivinen palaute tilanteissa, joissa akustoa puretaan, vaikka se on jo tyhjä. Vastaavasti myös kerrostalojen palautealgoritmeja on syytä tarkentaa, jotta suosittelija tuottaisi realistisempia ja käyttökelpoisempia suosituksia.
Suosittelijan jatkokehityksessä voidaan harkita myös uusien toimintavaihtoehtojen lisäämistä agentille. Esimerkiksi ylimääräisen energian myynti sähköverkkoon olisi hyödyllinen lisäominaisuus tilanteissa, joissa tuotanto ylittää kulutuksen.
Aiemmin on havaittu, että suosittelija tuottaa eri tuloksia eri algoritmin läpikäyntikerroilla. Tämän vuoksi suositusten laatua voitaisiin parantaa ajamalla algoritmi useita kertoja ja valitsemalla tuloksista parhaat skenaariot.
Jatkokehityksenä suosittelijaa voidaan testata todellisen kohteen datalla. Tämä mahdollistaisi suosittelijan päätösten kustannusten vertaamisen toteutuneisiin kustannuksiin ja antaisi arvokasta tietoa algoritmin käytännön toimivuudesta.
Kirjoittaja:
Alma Pohjonen, projektiasiantuntija, Karelia-ammattikorkeakoulu
Lähteet:
Pohjonen, A. 2025. Energiayhteisöjen energiavirtojen hallinta. Ennustus ja optimointi koneoppimisen avulla. Diplomityö. Automaatiotekniikan DI-ohjelma. Tampereen yliopisto. Saatavissa: https://urn.fi/URN:NBN:fi:tuni-202503132744
Shengren, H., Vergara, P., Duque, E, M, S., Palensky, P. 2023. Optimal energy system scheduling using a constraint-aware reinforcement learning algorithm. International Journal of Electrical Power & Energy Systems. Volume 152,2023,109230, SSN 0142-0615. Saatavissa: https://doi.org/10.1016/j.ijepes.2023.109230.
Sutton RS., Barto AG. 2015. Reinforcement Learning: An introduction. Second edition. The MIT Press. https://www.andrew.cmu.edu/course/10-703/textbook/BartoSutton.pdf. 31.12.2024
